Hello again everyone!
Today is my last day of work with the CLIR CCEPS project. Since May of this year, I have been working on archival projects related to California’s water history. Having only had brief experience in archival work prior to this project, I appreciated the exposure to this field of work. I have a deeper appreciation for the time, effort, and meticulousness required in managing archives and preparing items for the public to have access to. My work is only a stepping stone towards a future finished digital collection featuring items from different libraries who are working together.
I first started my experience here at CCEPS by digitizing Boxes 1 & 3 of the Imperial Valley Records. I am actually quite happy to have scanned items relating to the Imperial Valley–I did not previously know much about this area and its history despite traveling through this region a few times. I actually think I may use some of the items dealing with the creation of the Salton Sea for a graduate school paper. So sometimes in this line of work, you may find something in the archives that you can use for your own research.
After that, I began working on the metadata for these items. Over the course of managing the metadata for over 100 items, I tried to be thorough, specific, and clear. I wanted to make sure that the metadata reflected the reality of the items, so that future patrons will be able to find what they’re interested in with ease. In recent weeks during the Fall semester, I have been consulting the digital libraries and archives of other institutions. As a result, I have been exposed to different “metadata styles.” I saw some metadata that was thorough, and some metadata that could have been more “meaty” in terms of subject terms. In previous entries, I have described my metadata creation thought process. Making sure the correct Library of Congress terms are used was part of my mission. I have tried my best to create metadata that will be most helpful to future patrons but also was produced efficiently.
In the midst of working on the metadata for my items, I took part in a trip to the Metropolitan Water District with my fellow CLIR CCEPS peers. There, we met with the district’s archivist and learned about how he handles his archives and how he worked with their social media team to advertise exhibits he created. While there, we also saw their two current exhibits he had worked on: “Turning on the Tap: 75 Years of Water Delivery to Southern California,” and “From the Archives Reaching for Water – Rex Brandt and Metropolitan.” Learning about how they handled social media to advertise their 75th anniversary exhibit has helped us at CLIR CCEPS figure out how we should handle social media for the CLIR project. Later, while working on metadata, I realized I had actually scanned one item that relates to the construction of the Colorado River Aqueduct: https://cdm15831.contentdm.oclc.org/cdm/ref/collection/cwd/id/4761
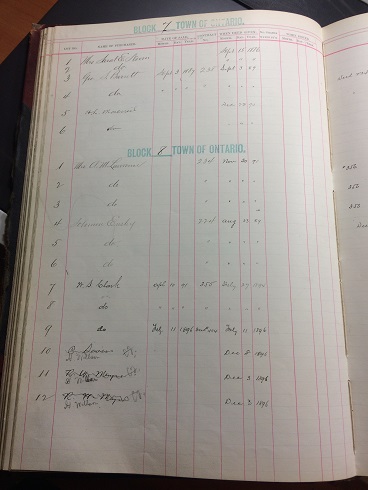
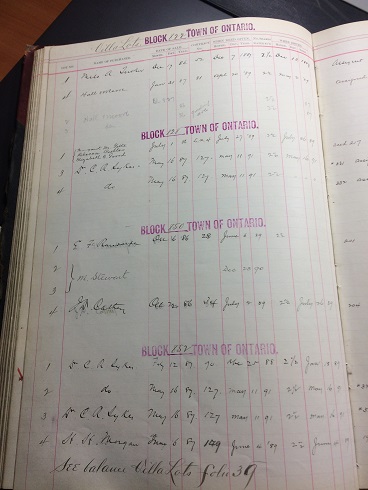
Since finishing my metadata, I began working on a land ledger from the Ontario City Library. My fellow CLIR CCEPS fellows will soon begin working on metadata for these items and uploading them on behalf of the Ontario City Library.
The CLIRWater project has given me the opportunity to explore archives from a different perspective, and this experience is one that I will carry with me moving forward in my master’s program at Claremont Graduate University.